モデルのデバッグ
本ページでは、Responsible AI Toolbox に含まれるモデルをデバッグ・アセスメントする技術を紹介します。
Responsible AI Toolbox での対応
Responsible AI Toolbox において、モデルのデバッグ・アセスメントに関連するところは最初の 3 つのステップ Identify (特定) → Diagnose (診断) → Mitigate (緩和) になり、UI 機能の Responsible AI Dashboard でカバーしているのは下図で緑でハイライトされている部分です。

caution
Mitigate は Responsible AI Dashboard の機能では提供されていませんが、Responsible AI Toolbox Mitigate や Fairlearn ライブラリを用いることが実行できます。
Responsible AI Toolbox のバックエンドで利用されているツールを紹介します。
| 機能 | ベース技術 | 概要 |
|---|---|---|
| Error Analysis | Error Analysis | モデルの誤差の大きいコホートを特定します。 |
| Fairness Assessment | Fairlearn | モデルの公平性を評価します。 |
| Model Interpretability | InterpretML | ブラックボックスなモデルに説明性を付与します。 |
| Counterfactual Analysis | DiCE | 予測値を変化させる反実仮想のデータを生成します。 |
Error Analysis
Error Analysis では学習済みの機械学習モデルの誤差の大きいコホート (データのサブセット) を特定します。機械学習モデルを評価する際、精度 73.8 % などと集計された数値で見ることが多いと思います (下図) が、ユースケース次第ではそれでは不十分な場合があります。
集計された数値指標では、誤差がデータのどこに潜んでいるのかはこれでは分かりません。次のようなケースでは特に問題になりやすいです。
- 病理診断モデルにおいて子供や高齢者の誤差が他と比べて大きい
- 与信モデルや異常検知モデルなどで特定の性別・人種だけ誤差大きい
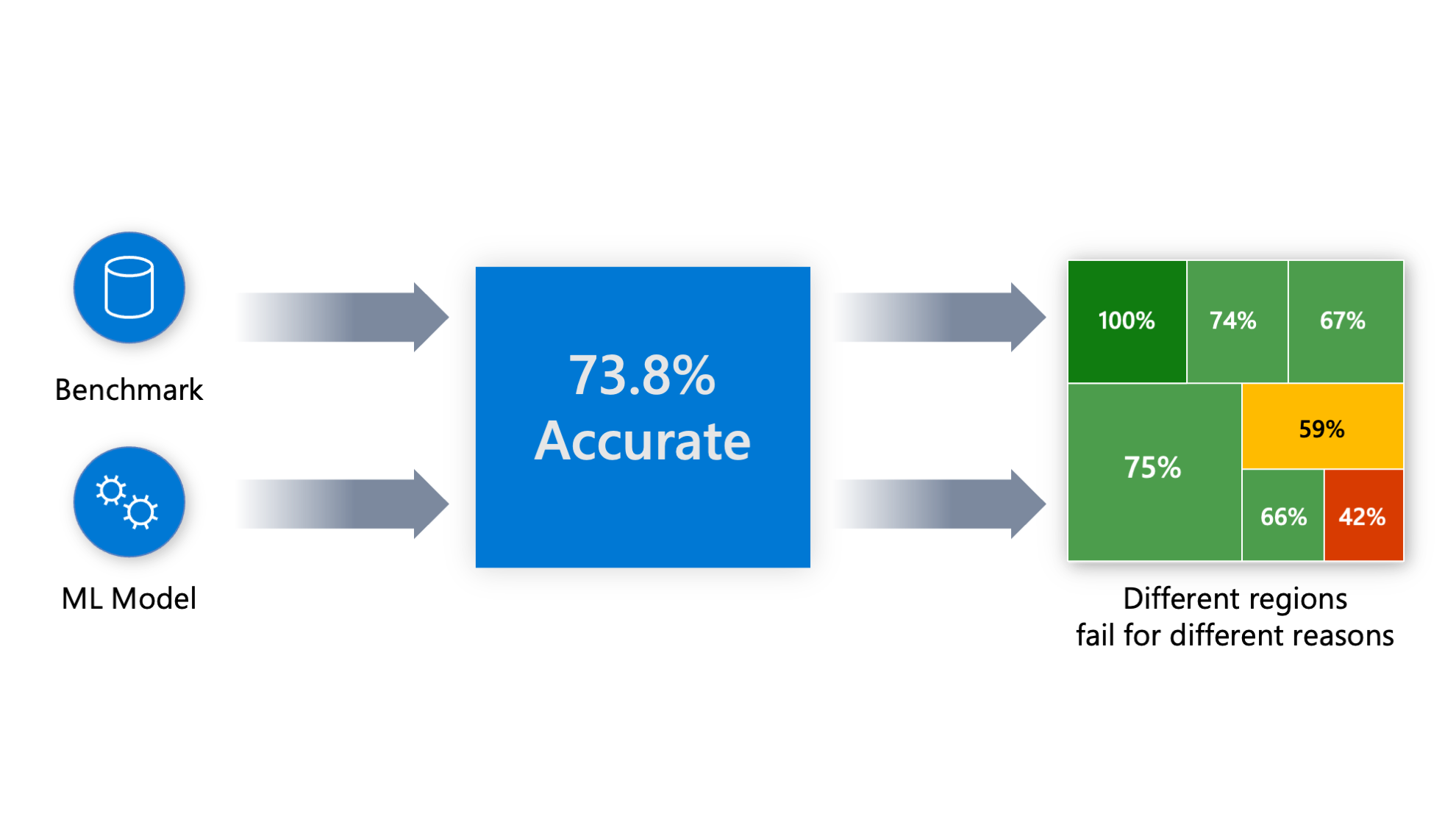
誤差が大きくなる・小さくなるコホートを特定することで、ステークホルダーに対してモデルの潜在的なリスクを伝えることができたり、誤差が大きいコホートのデータの品質を改善することで精度が向上することが期待できます。
なお、Error Analysis は Responsible AI Toolbox に直接組み込まれています。
参考情報
Fairness Assessment
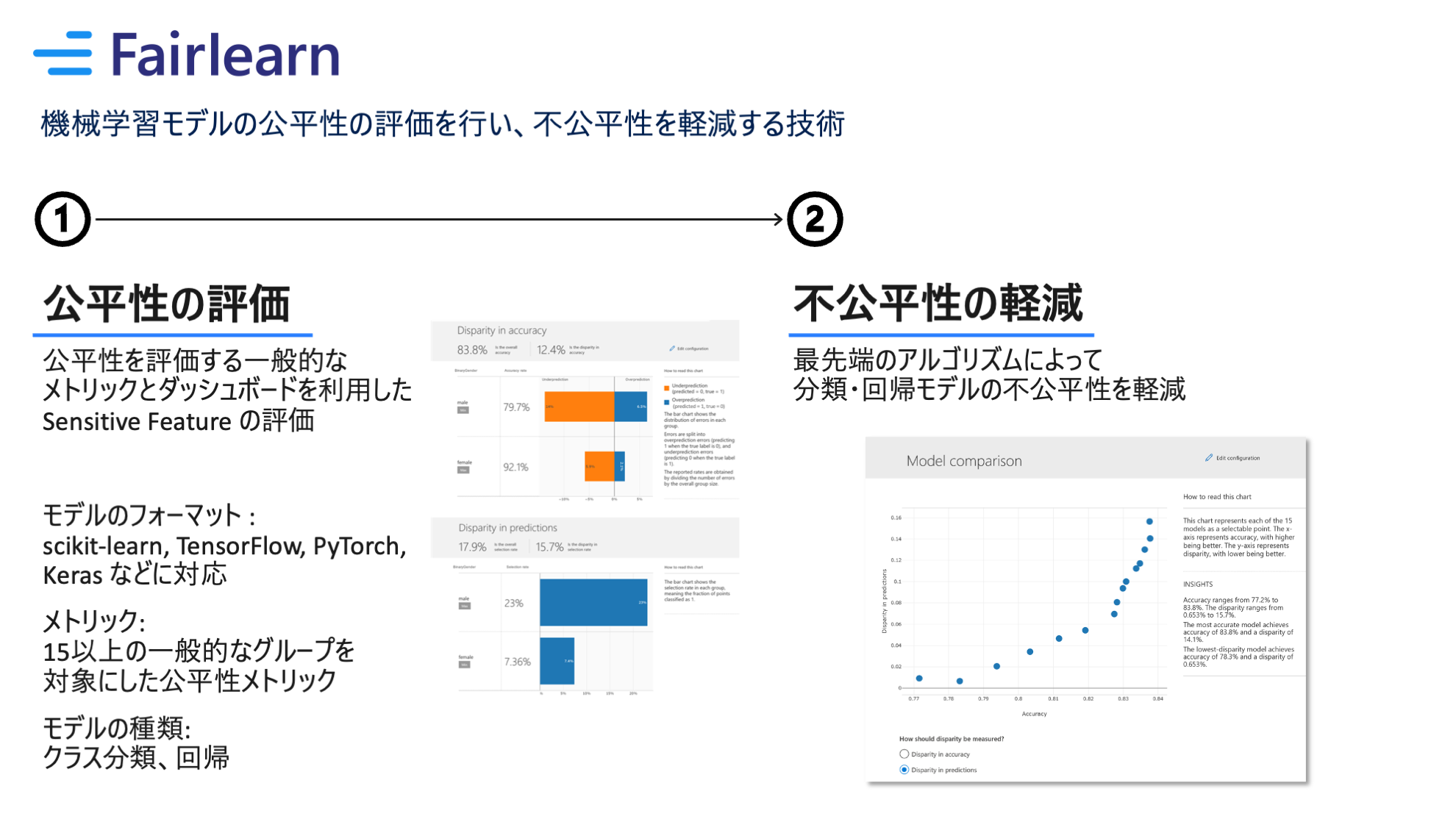
Fairness Assessment では学習済み機械学習モデルの公平性の評価を行います。Python ライブラリの Fairlearn をベースにしています。
人種、ジェンダー、年齢などによってマイナスの影響がでるような機械学習モデルは許容されない場合があるため注意が必要です。
note
モデルから不公平性を軽減する機能は Responsible AI Toolbox に含まれていませんが、Fairlearn には含まれています。
ライブラリ : Fairlearn
Fairlearn は機械学習モデルの公平性を評価し、必要に応じて不公平性を軽減することができる Python ライブラリです。
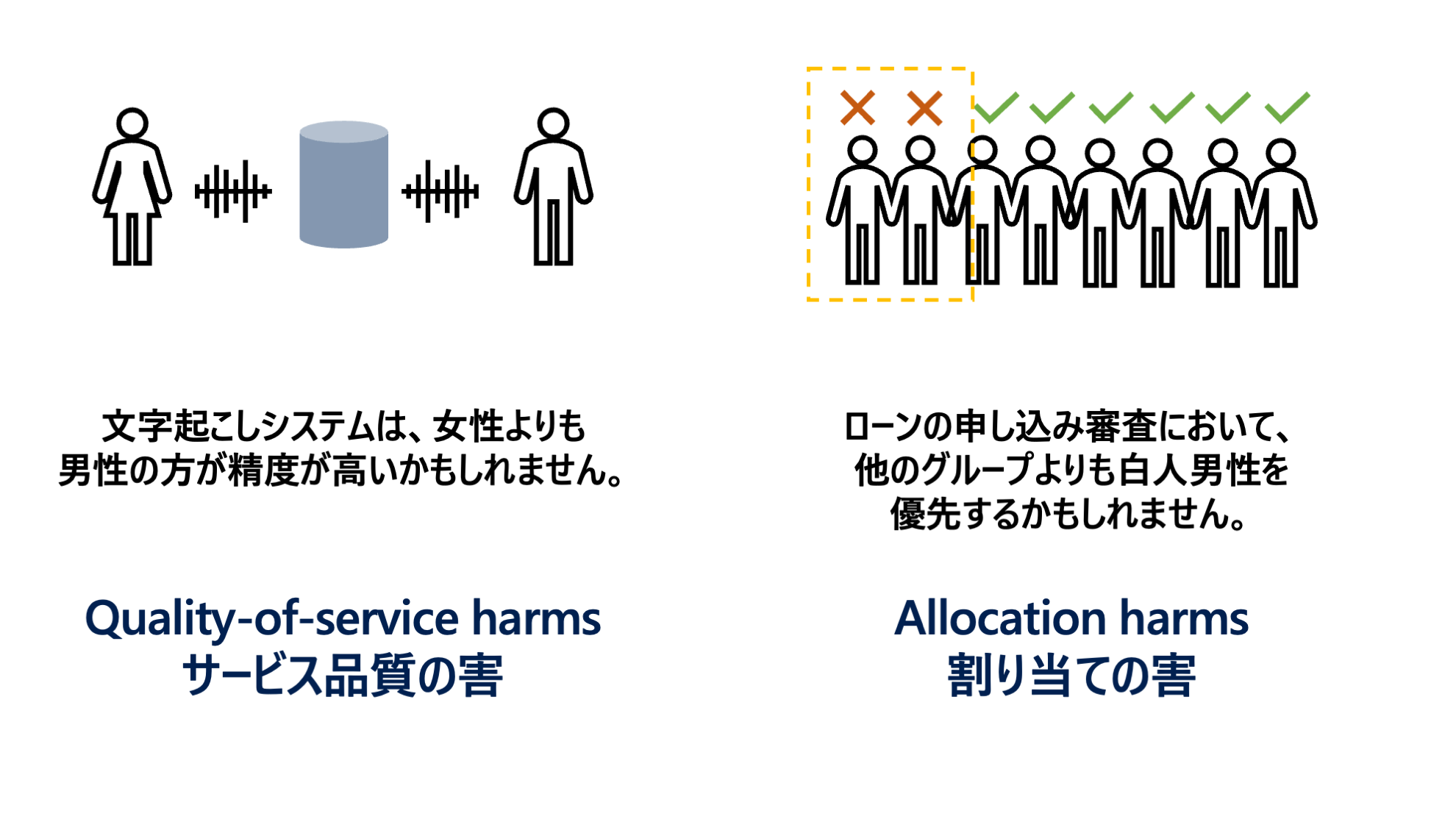
Fairlearn が想定している不公平性による損害 (Harm) のパターンは Quality-of-service harms と Allocation harms の 2 通りです。
参考情報
Model Interpretability
学習モデルに説明性を付与する機能を提供します。Python ライブラリの InterpretML をベースにしています。
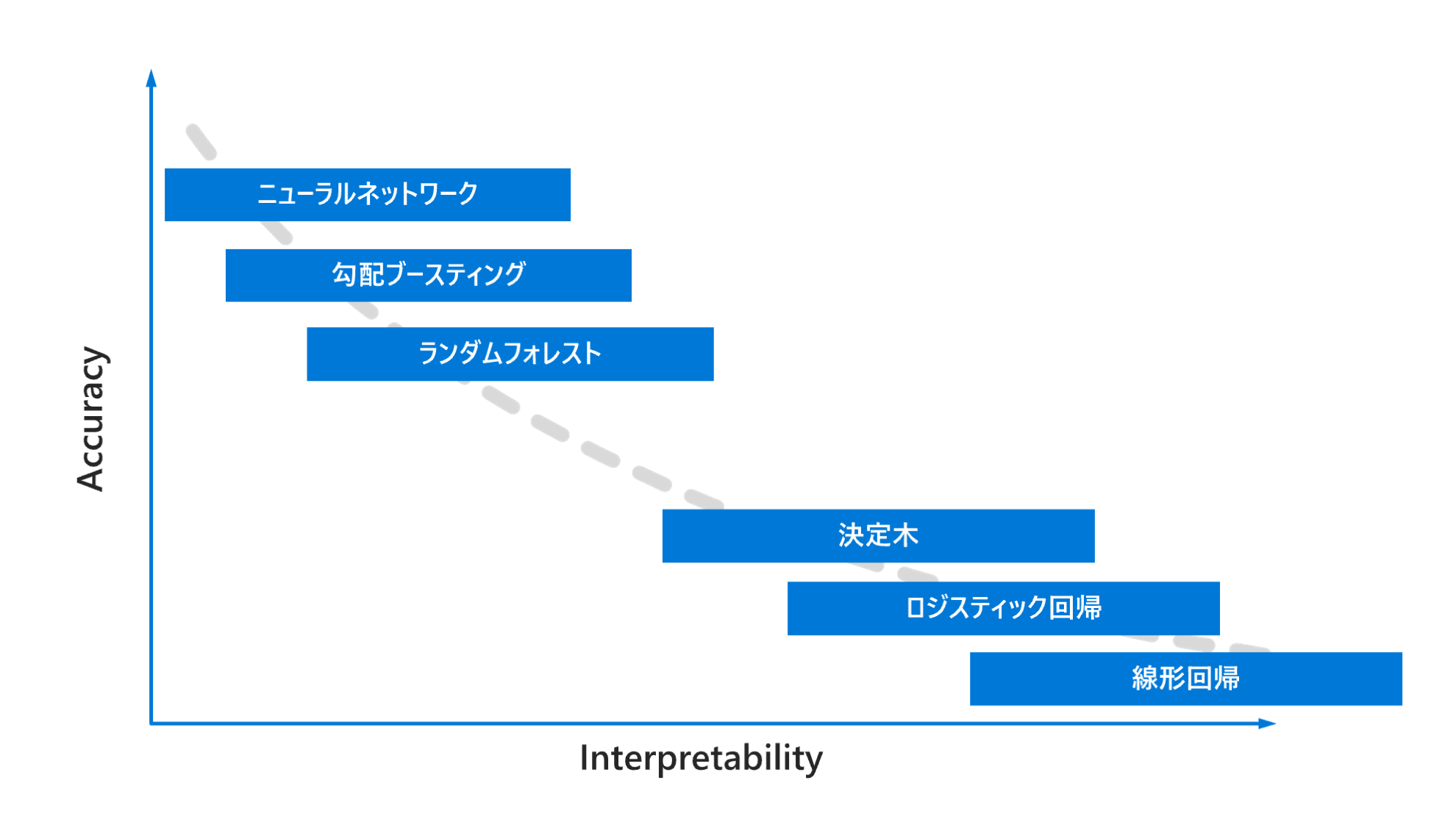
解釈可能性とモデル精度のトレードオフ
下記の図にあるように一般的には機械学習モデルの精度 (Accuracy) と解釈可能性 (Interpretability) にはトレードオフがあります。精度が高いニューラルネットワークのモデルが開発できたとしても、高い透明性が求められるようなビジネス要件の観点から採用されない・できないことがあります。
解釈可能性 (Interpretability) & 説明性 (Explanability) とは?
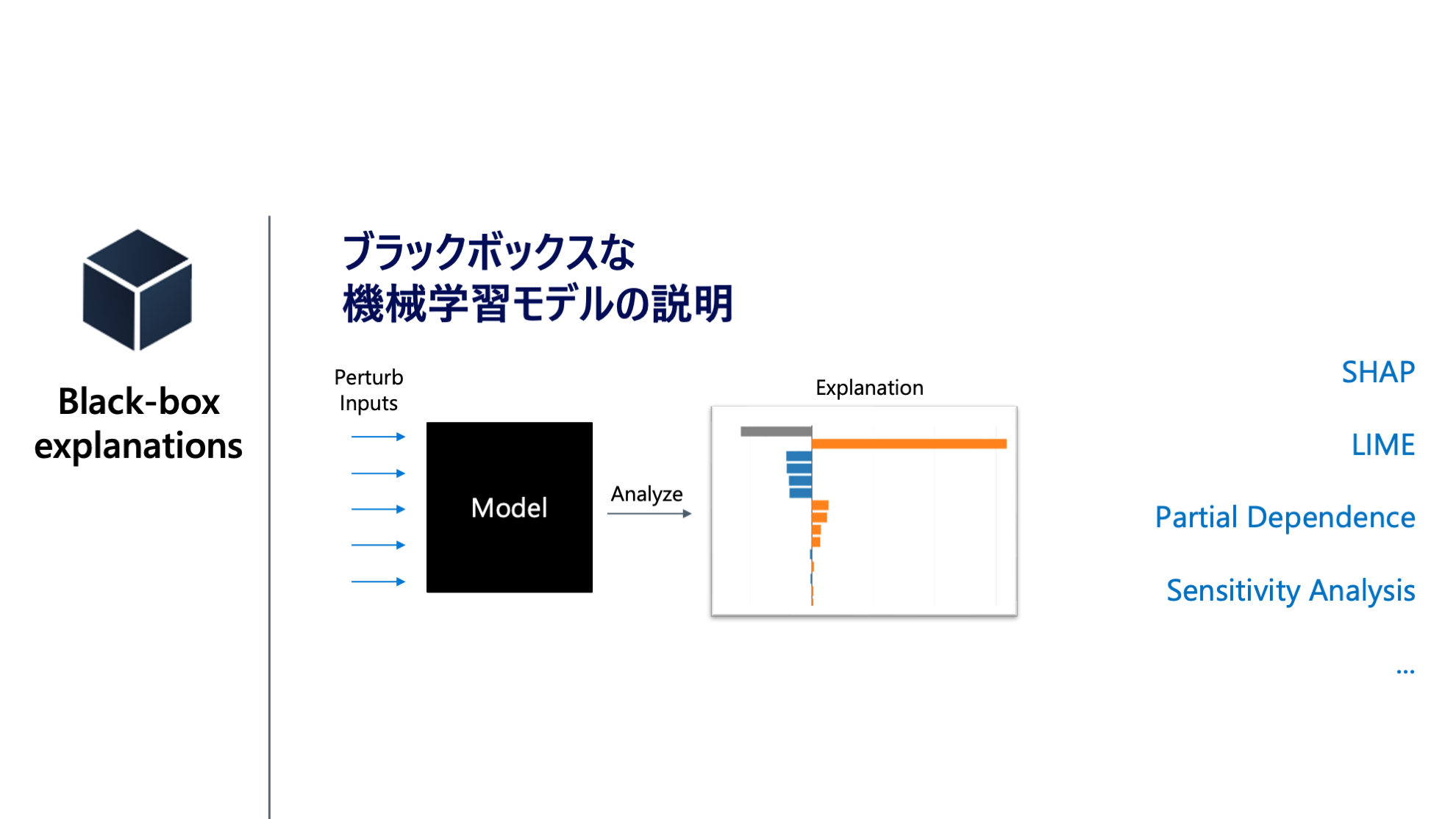
Explainability
機械学習モデルの挙動を人間が説明できることを指します。通常複雑なモデル (Blackbox) を Agnostic な説明手法を用いてモデルに対する入力と出力の関係性からモデルを説明します。
Interpretability
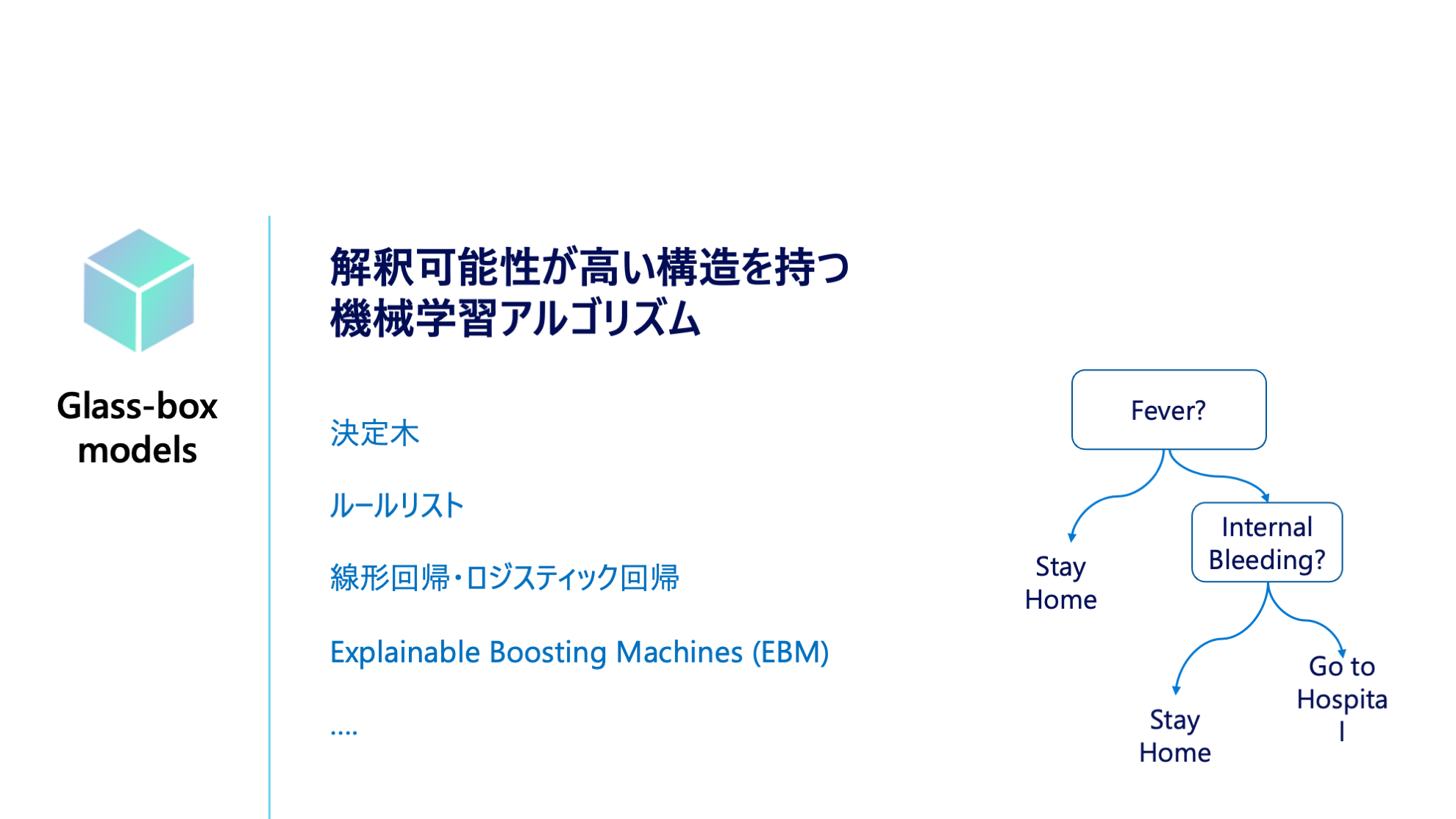
予測値を算出するまでのアルゴリズム内部の過程が、人間が解釈できる機械学習モデル (Glassbox) を指します。
ライブラリ : InterpretML

InterpretML は、主要な「解釈可能性が高い Glass-box なモデル」 と 「任意の学習済みモデル (Black-box) に対する説明性付与手法」が実装されているライブラリ群です。それぞれに共通してモデル全体の傾向を見る大域的な説明とテストデータ個々の予測値に対する局所的な説明があります。
主要なアルゴリズム
Global Surrogate
グローバルなモデル解釈方法。学習済みモデルへの入力データとその予測値を再度線形回帰などの解釈可能なモデルで学習し直して、モデル解釈をするアプローチ方法。InterpretML では LightGBM や線形回帰のモデルが利用できます。
SHAP
SHAP (SHapley Additive exPlanations) はゲーム理論のシャープレイ値の枠組みを利用して、モデルの種類に関わらず、ここのデータの特徴量ごとの貢献度をみることができます。SHAP 単体でもライブラリが公開されています。
Explainable Boosting Machines (EBM)
Explainable Boosting Machines (EBM) は、一般化加法モデル (GAM) に交互作用項を組み込んだモデル (GA2M) を高速に推定するアルゴリズムです。
それぞれの特徴量 は関数 で表現されています。線形回帰などの線形モデルとは違い目的変数 との関係性は線形性は前提としていません。この関数を推定する方法はいくつかありますが、EBM ではこの関数をブースティングで推定します。また交互作用項を推定するアルゴリズム (FAST) も実装されており精度向上に寄与しています。
参考情報
Counterfactual Analysis and What If
学習済みモデルが出力する予測値を変化させる反実仮想の入力データを生成します。反実仮想の世界「もし入力データが xxx だったら予測結果は xxx に変わります。」を用いて機械学習モデルを評価します。Python ライブラリの DiCE をベースにしています。
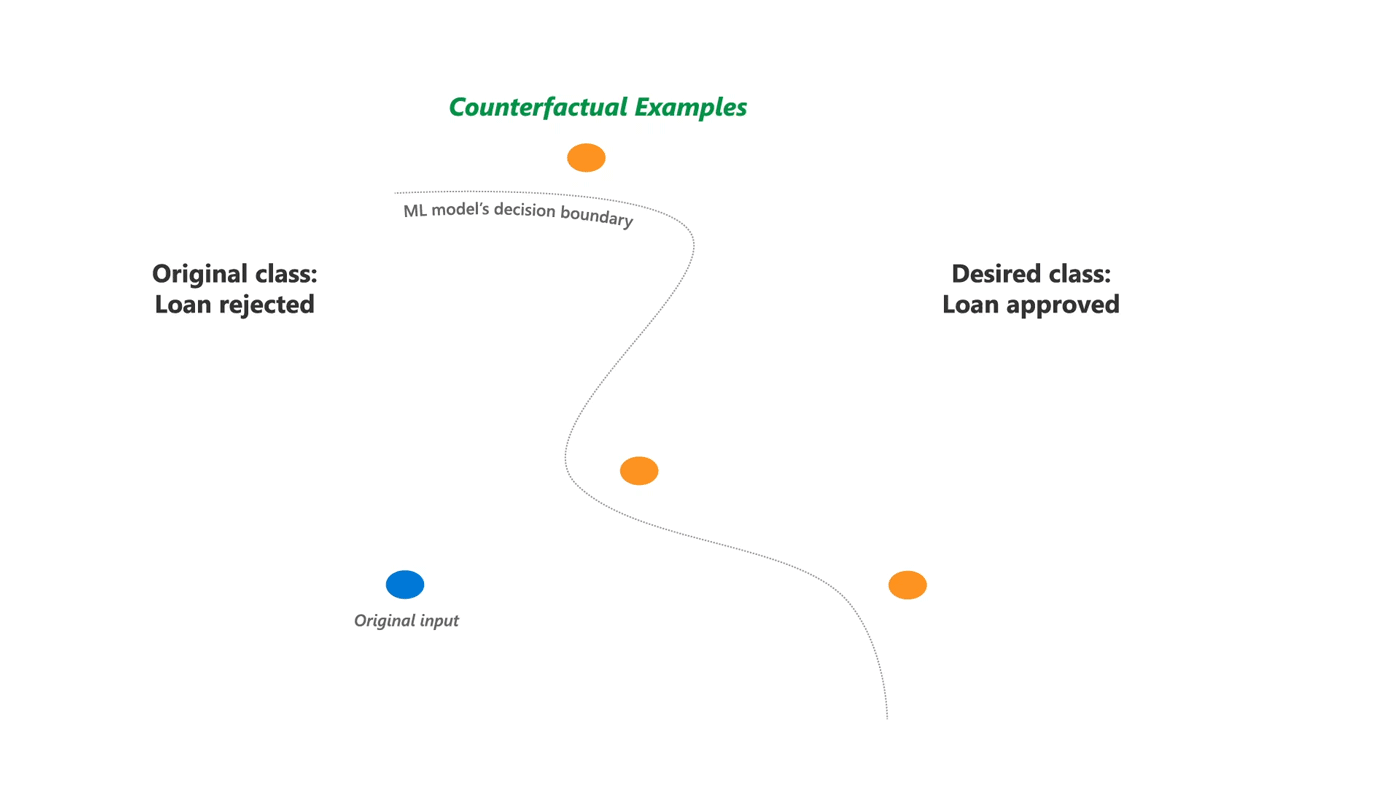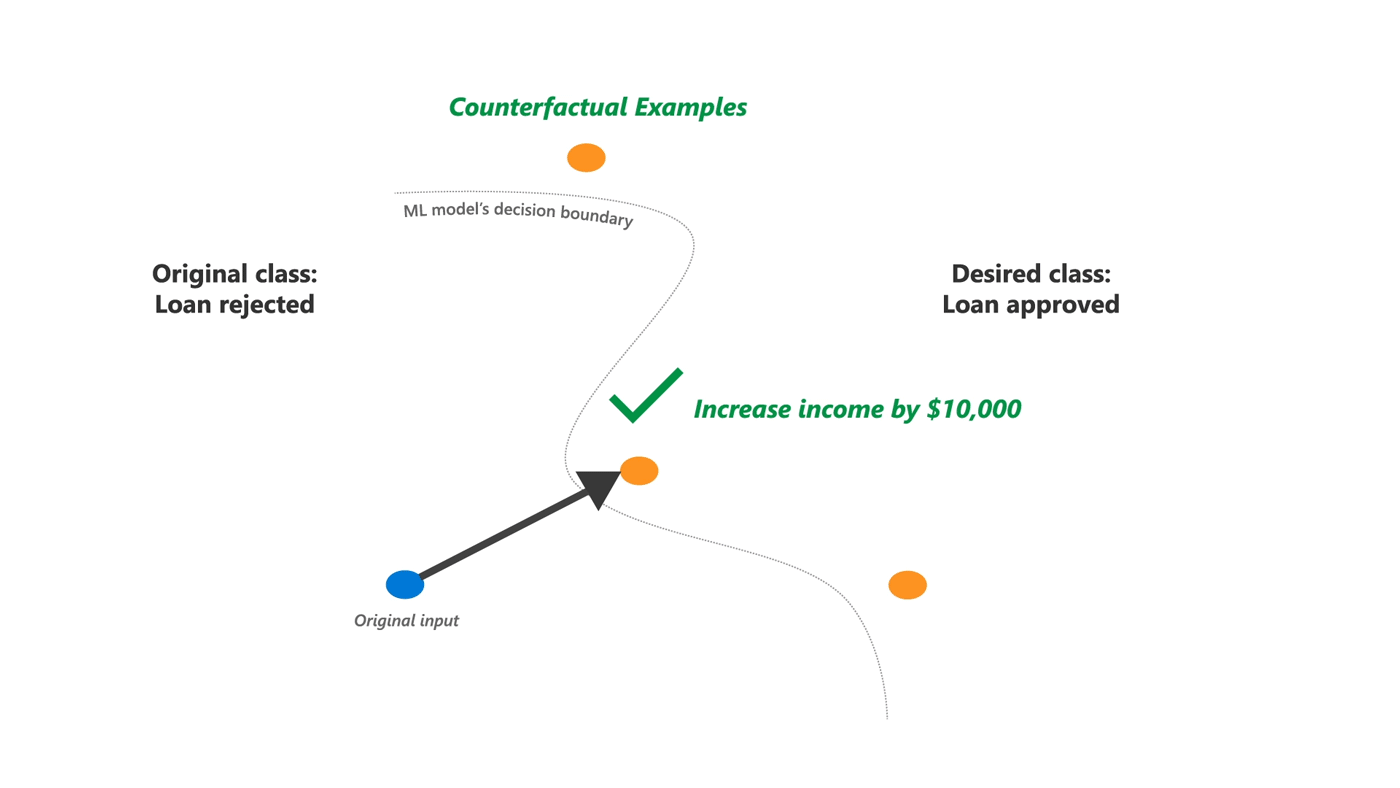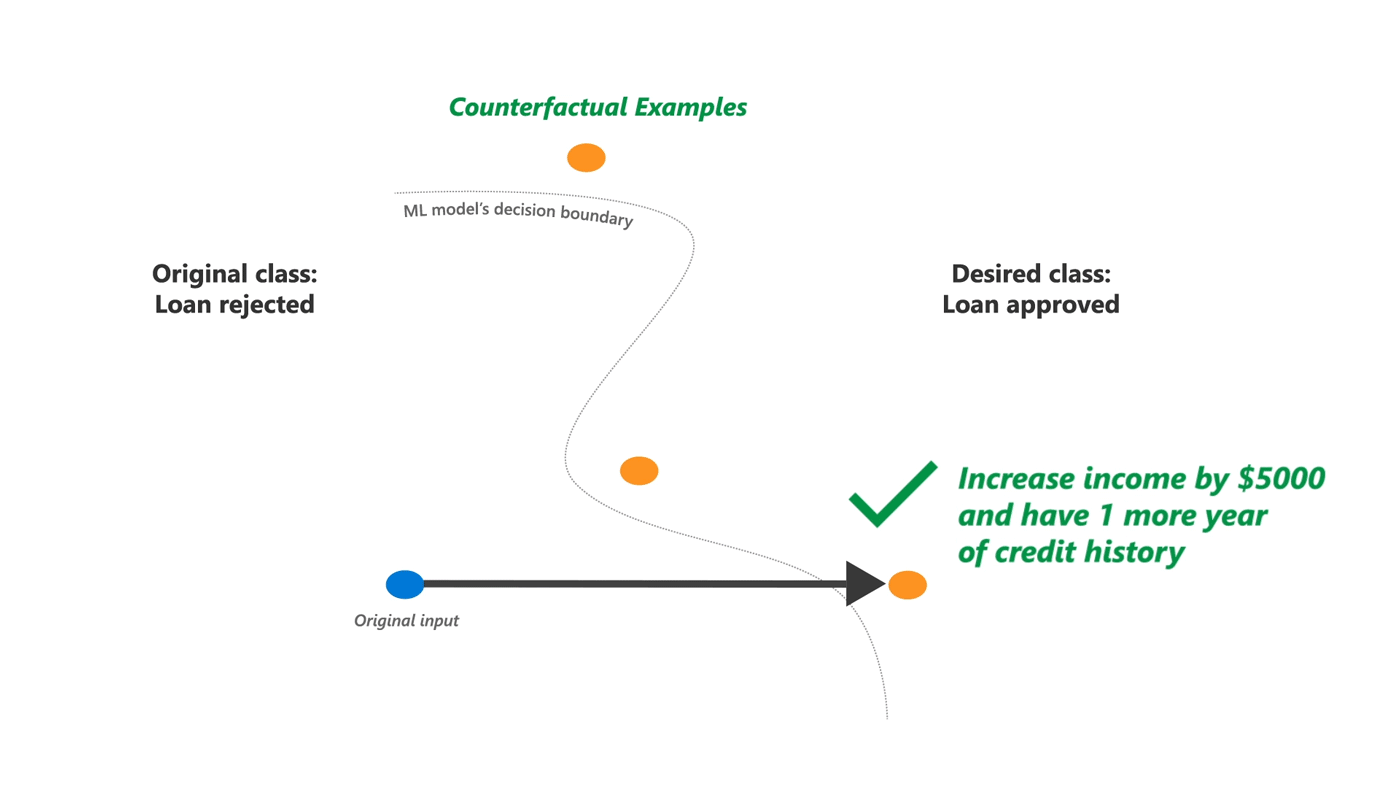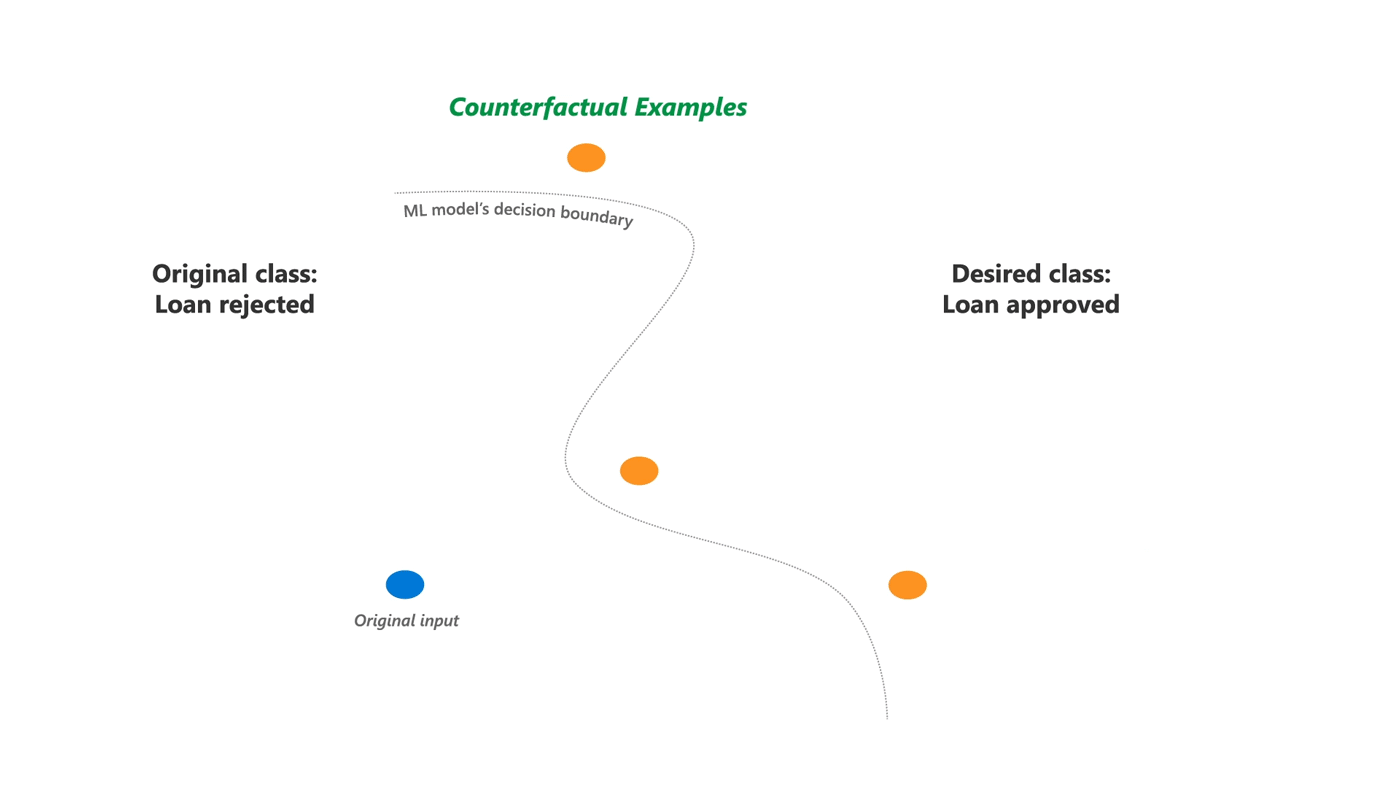
例えば住宅ローンの審査が結果として拒否されたケースの場合、どういった入力データ (勤続年数、借入金額、年齢 etc) であればローン審査を通過できると機械学習モデルが予測するのかを教えてくれます。
ライブラリ : DiCE

DiCE (Diverse Counterfactual Explanations) は Microsoft が主導で開発している反実仮想説明 (Counterfactual Explanation, CE) の Python ライブラリです。