MLOps のプラクティス
本ページでは MLOps のプラクティスと Azure Machine Learning で実践する際に利用する機能を紹介します。
🎨 7 つのプラクティス
MLOps を導入する際の基本原則を挙げます。
コード、データ、モデルを管理する。
機械学習のシステムはコードだけでなくデータが品質に大きく影響をします。そのためコードだけでなく、データを管理する必要があります。
複数の実行環境を使用する。
開発環境、テスト環境、本番環境とワークロードに応じて環境を分けることで、環境ごとのアクセス制御を設定することでセキュリティレベルを上げます。
インフラストラクチャと構成をコードとして管理する。
環境を複製したり再構築することに備えて、迅速に構築ができるようにインフラをコードで管理します。
実験管理と追跡をする。
実験で利用したアセットやモデル指標などの出力を管理します。またモデルや推論環境に紐づく実験を追跡します。
コードのテストを行い、データの整合性を検証し、モデルの品質を確認する。
実験で利用するコードやデータは機械学習モデルの品質に大きく影響するため、テストを実行することが大事です。
継続的インテグレーションとデリバリーによる自動化。
継続的インテグレーション (CI) によるテストの自動化や再現性の確認、継続的デリバリー (CD) によるデプロイメントの自動化を行います。
推論環境、モデル精度、データ特徴を監視する。
推論環境やその上で動くモデルの精度、また新しいデータを監視して再学習が必要かどうかを把握する必要があります。
🚀 Azure Machine Learning を利用した MLOps の実現
MLOps を Azure Machine Learning で実装する際に利用する代表的な機能を挙げます。
🧠 再現性のあるモデル学習・推論
Azure Machine Learning のパイプライン (Pipeline) を使用して、再現性の高い機械学習ライフサイクル (データ準備、特徴量エンジニアリング、モデル学習、ハイパーパラメータチューニング、モデル評価 etc) を実装することができます。
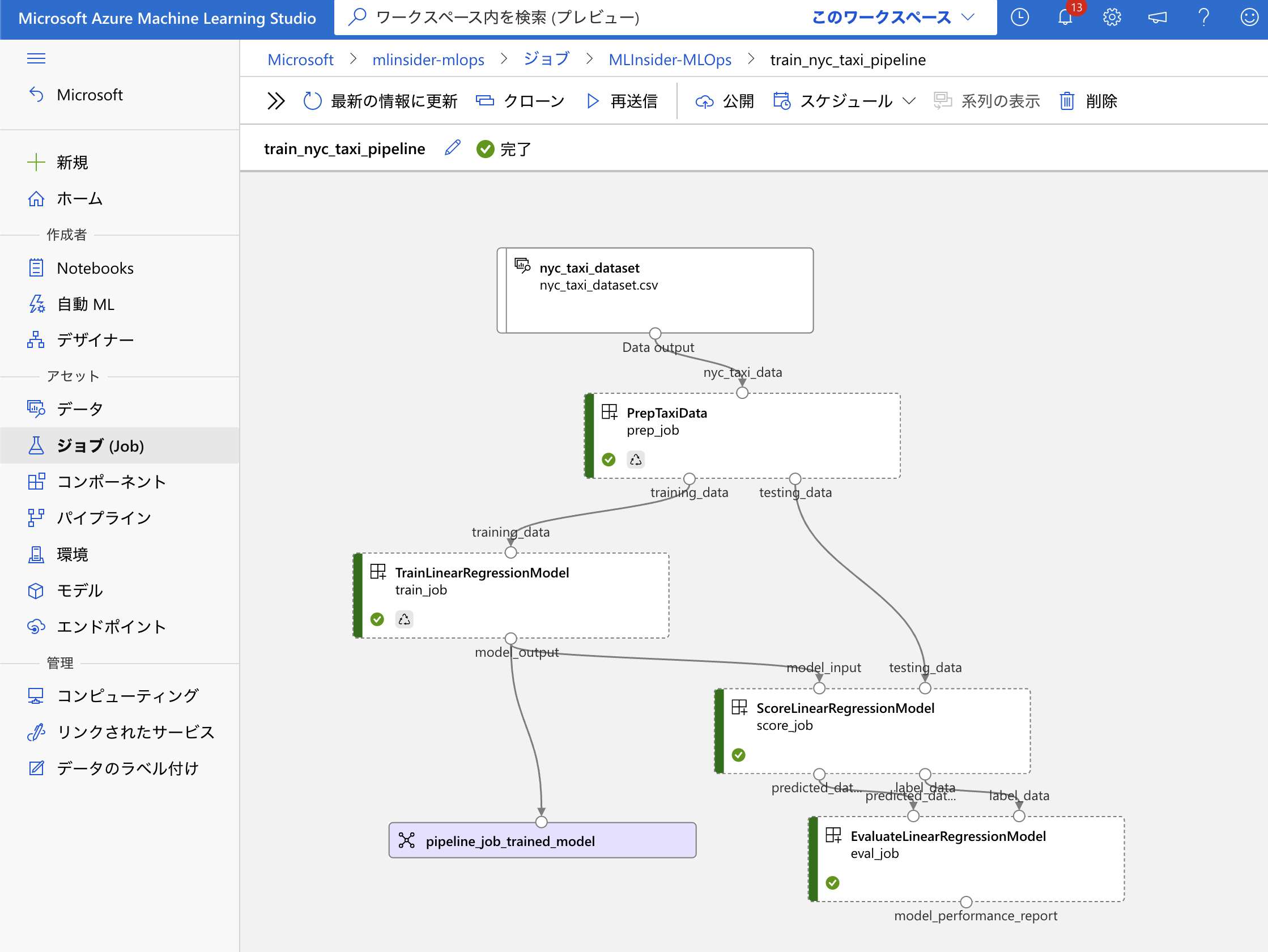
また、デザイナーの機能を用いることで UI 操作のみでコード操作無しに Pipeline を作成することができます。デザイナーで用いることができるコンポーネント (Component) はユーザー自身で作成して、Workspace 内部で共有して使用することもできます。
note
Azure Machine Learning Pipeline による推論の形態は、バッチ推論 を想定しています。
参考情報
🌐 再現性のあるソフトウェア環境
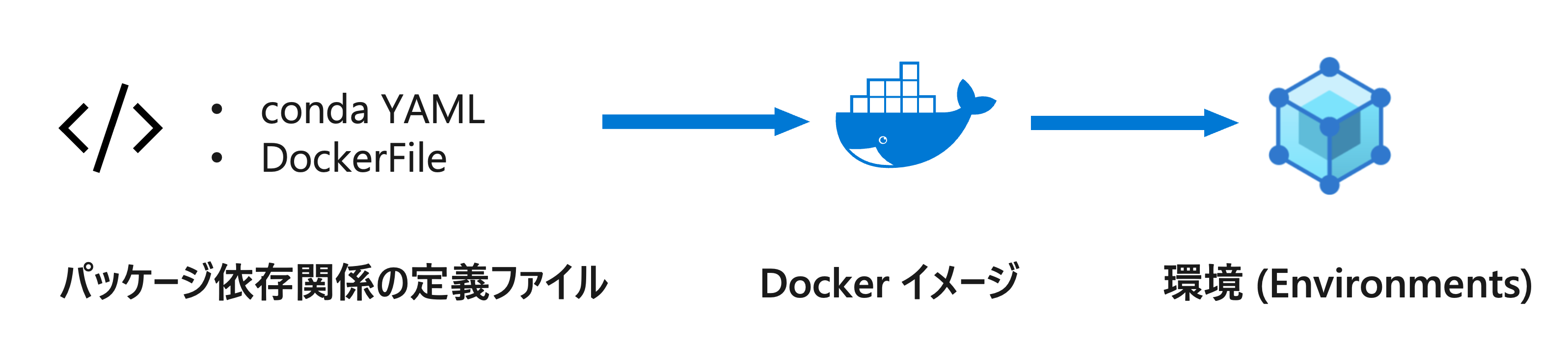
Azure Machine Learning の環境 (Environment) の機能を用いて、モデル学習や推論環境で利用する Python ライブラリなどのソフトウェアを管理します。
特に Python のライブラリの管理は煩雑になっているため、再現性に苦慮することが多いため、早い段階から環境 (Enviornment) を用いたソフトウェア管理に取り組むことを推奨します。
参考情報
📦 モデルの運用管理
Azure Machine Learning を用いて、実験を紐づけたモデル登録と推論環境へのデプロイを行うことができます。
モデル登録と追跡
あらゆる実験環境で構築されたモデルは、MLflow (Python)、Azure CLI や UI (Azure ML studio) 経由で Azure Machine Learning のモデル (Model) の機能を用いて登録することができます。
また、モデル登録時に実験の情報を紐づけておくことで、登録済みモデルを構築した元のソースコード、データ、パラメータなどのメタデータを追跡することができます。
モデルのデプロイ
Azure Machine Learning では Batch Endpoint と呼ばれるバッチ推論の形態の推論環境と、Online Endpoint と呼ばれるリアルタイム推論の形態の推論環境を提供しています。比較は 推論に特化した計算リソース を参照ください。
また、ユーザーへの影響を極力抑えて安全にデプロイするための仕組みとして Blue/Green デプロイメントもサポートしています。
参考情報
♻️ エンドツーエンド監査証跡
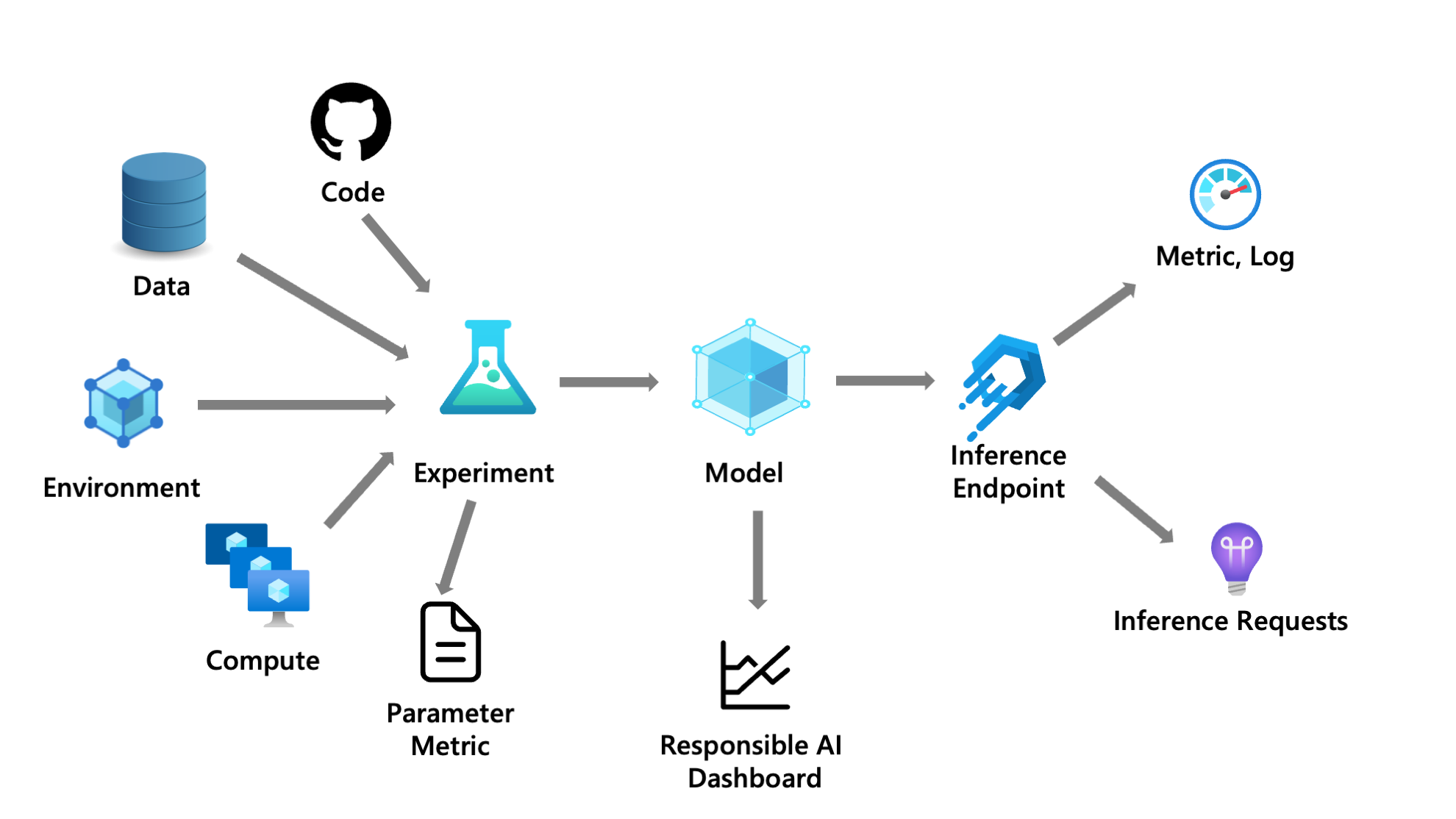
Azure Machine Learning 上で機械学習ライフサイクルを回すことで、エンドツーエンドでの監査証跡が可能になります。
- コードのスナップショットと Git のメタデータ (リポジトリ、ブランチ、コミット ID)
- データとそのバージョン
- 計算リソースのメタデータ
- モデルのパラメータやメトリック (MLflow)
- 出力ログやファイル
- その他、実験の実行時間、作成者、タグ...
- 学習済みモデルと関連する実験のメタデータ
- 説明性に関するダッシュボードやレポート
- 推論環境と関連するモデルのメタデータ
📣 通知・アラート
Azure Event Grid との連携機能を用いて、機械学習ライフサイクルで発生したイベント (実験完了、モデル登録、デプロイ完了、データドリフト etc) をキャッチしアクションを起こせる仕組みを作ることができます。
参考
📊 モニタリング
Azure Monitor を利用して監視の仕組みを作ることができます。例えば推論環境における CPU 利用率や接続数などのログや、入出力データを取得し、再学習に役立てることができます。
サンプルのモニタリング用のダッシュボードが公開されており、クイックに実装することができます。

参考
📈 再学習の実行
多くの機械学習モデルはデータの変化や要件の変化に対応すべく、再学習することが求められます。Azure Machine Learning パイプライン (Pipeline) の仕組みを利用して、新しいデータで構築したモデルを古いものと比較し、あらかじめ設定した閾値・条件に基づいて置換するかどうかを選択するようなフローを構築することができます。
🚘 機械学習ライフサイクルの自動化
Azure Machine Learning パイプライン (Pipeline) 以外にも、GitHub Actions や Azure Pipeline を利用して、Git 操作をトリガーにした自動化を実装することができます。
例
- Data Scientist がコードを Commit/Push するタイミングでテストを実行する
- コードや利用しているパッケージの脆弱性を定期的にスキャンする
- モデル登録をトリガーにして、推論アプリケーションを構築する
MLflow を用いた MLOps
MLflow は機械学習の実験管理やモデル管理などをサポートするオープンソースライブラリです。Azure Machine Learning は MLflow の API をサポートしており、MLOps のシナリオで利用することができます。
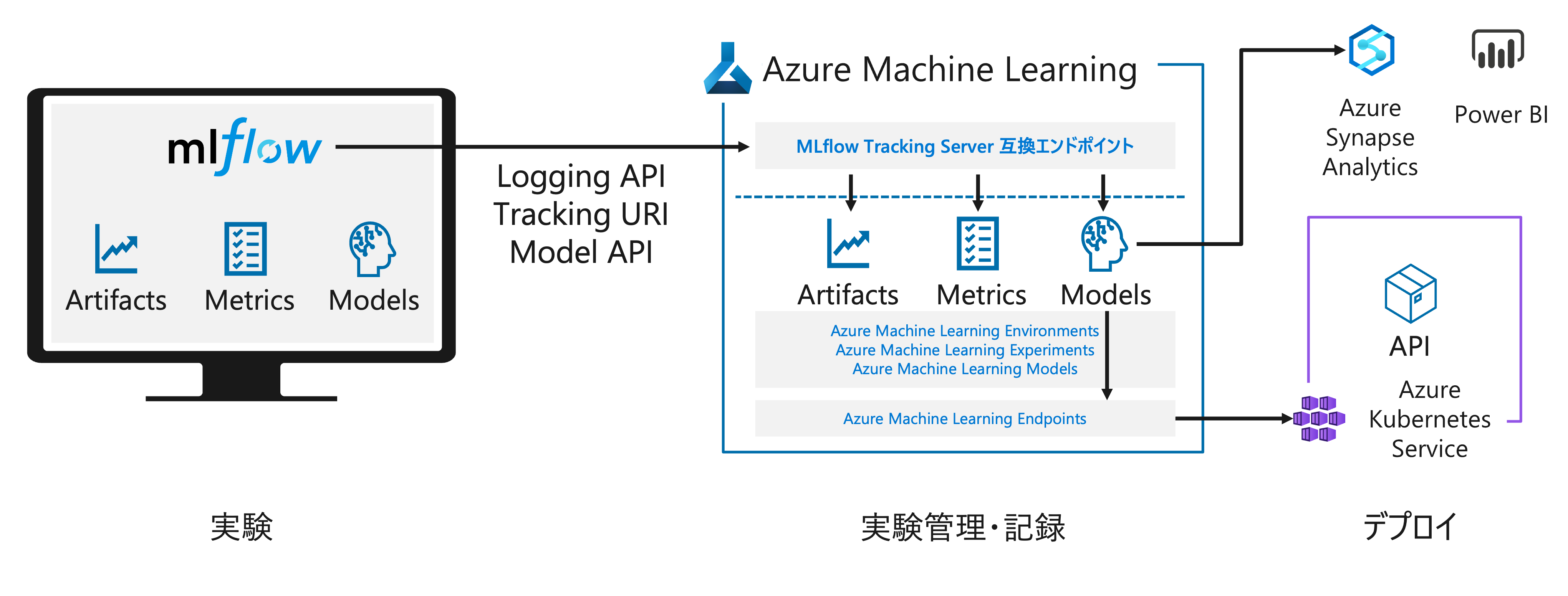
- 実験の追跡
- モデル登録
- MLflow 形式モデルのデプロイ
- MLflow Project によるモデル学習 (Preview)