Notebook の Job への変換
Prototyping Loop から Training Loop に遷移する際、Data Scientist の成果物である Notebook を Azure Machine Learning の Job で実行する形態に変更することが推奨されます。 本ページでは Notebook を Azure Machine Learning Job で実行するためのステップを説明します。
note
機械学習ライフサイクルにおける Loop の考え方は MLOps とは - 機械学習のライフサイクル" のセクションを確認してください。
全体の流れ
Notebook で試行錯誤した成果物を Azure Machine Learning の Job で実行する形態に変更するまでの大まかな流れを示します。
- Notebook のリファクタリング
- Notebook をリファクタリングし、他の人に共有しメンテナンスできる状態にします。
- アセットの疎結合
データ、計算環境、環境といったアセットの部分を Notebook やコードから切り離して Azure Machine Learning で管理するようにします。
- ジョブの作成
- YAML ファイルを作成し、Azure Machine Learning の Job を実行します。
Notebook は Python スクリプトで変更され、GitHub で管理します。また関連するアセットは Azure Machine Learning Workspace/Registry で管理することで、チームに共有したり、可観測性・再現性を向上させます。
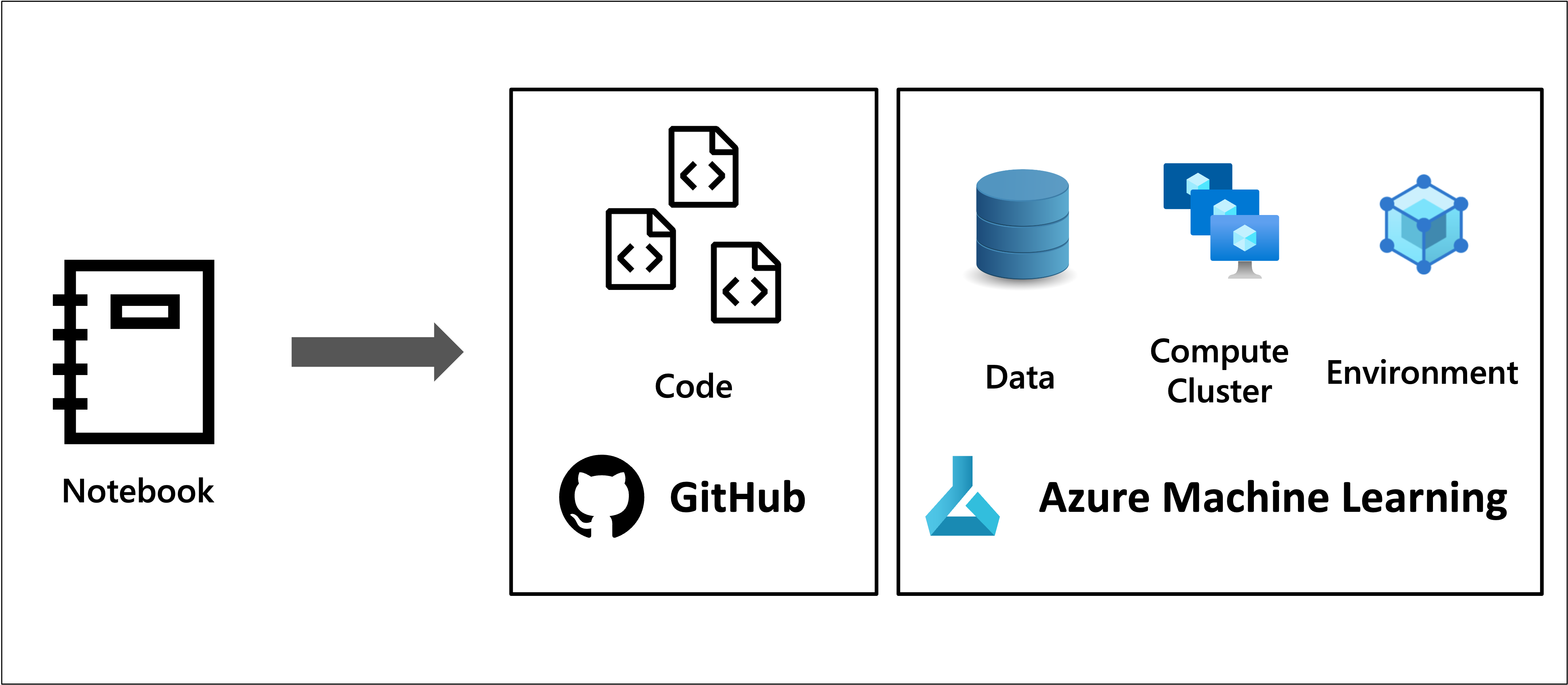
1. Notebook のリファクタリング
Notebook は属人化していることが多いため、次のような取り組みを行います。
不要なコードを削除する
- Notebook の中では探索的な目的で利用されるコードがあります。
汎用的なコードを関数 (function) にする
- 単体テストが容易になり、保守性が向上します。
Notebook を Python スクリプトに変換する
- 一般的な python コマンドから実行できるようにします。
note
papermill を使うことで Notebook をそのままコマンド実行することができます。
参考情報
2. アセットの疎結合
コードの中で利用される次のアセットを Azure Machine Learning のアセット管理の機能に置き換えることで、チームで共有し開発・運用管理の効率性を上げます。
データ
- モデル学習で用いるデータを管理します。
- Azure Machine Learning の
Dataを利用します。- データが格納されている Azure Storage へのパスを指定します。
- Python スクリプトの実行時にデータファイルのパスを引数に設定できるようにコードを編集します。
計算環境
- 計算環境を管理します。
- Azure Machine Learning の
Compute Clusterを利用します。- Azure VM の中から使いたいスペックと台数を指定します。
環境
- Python ライブラリを管理します。
- Azure Machine Learning の
Environmentを利用します。- conda の YAML ファイルや Dockerfile を指定します。
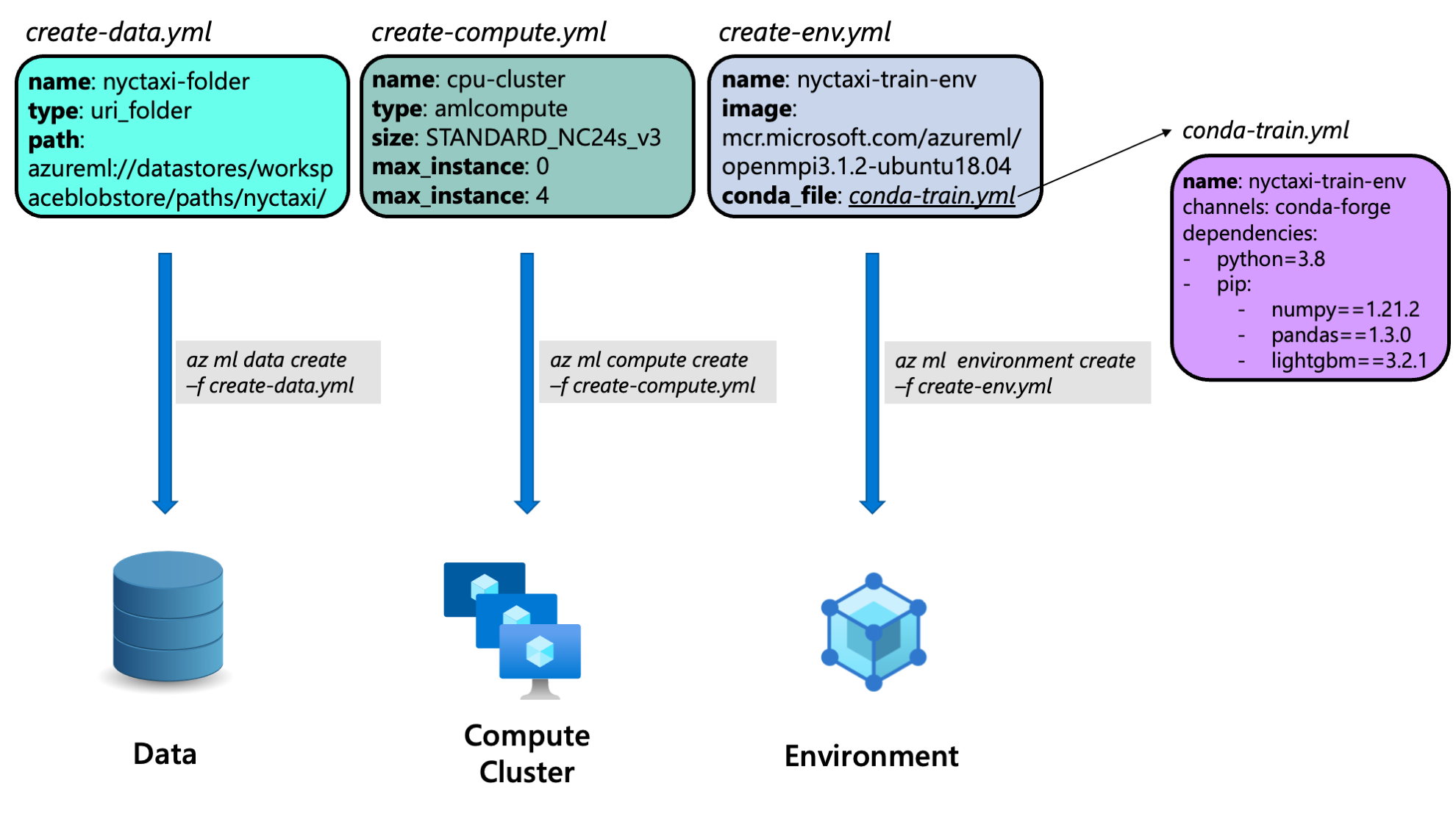
参考情報
3. ジョブの作成
Azure Machine Learning の Job を利用して実行します。必要なものは次に挙げるものです。
YAML ファイル
各アセットの情報を記載します。
- コード : Python スクリプトのパス
- Azure Machine Learning のアセット
Data: 名前、バージョン、アクセス方法Environment: 名前、バージョンCompute Clusters: 名前
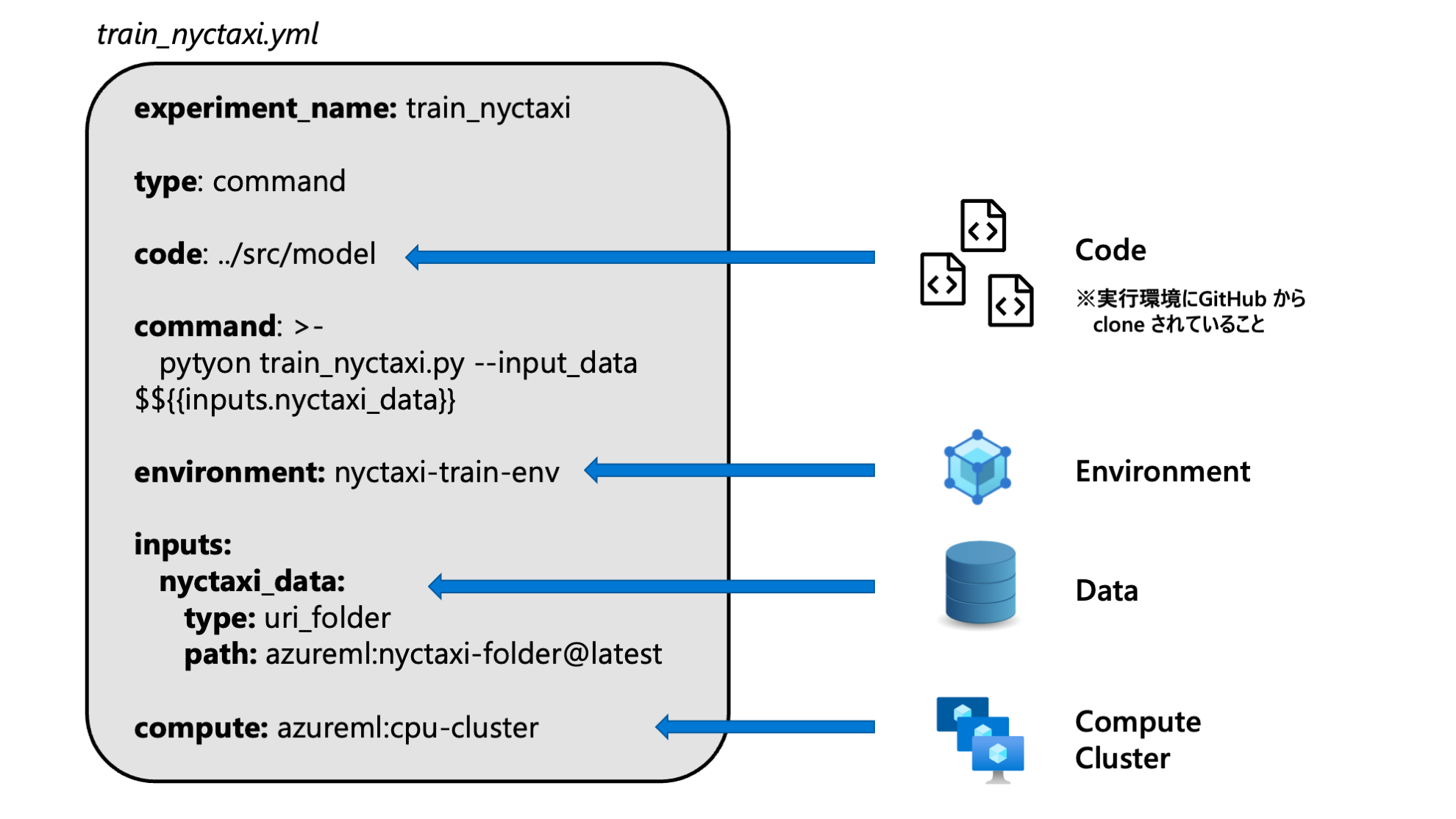
Azure CLI 実行環境
実行環境に Azure CLI の ml 拡張機能をインストールします。
# 既存拡張機能のアンインストール
az extension remove -n azure-cli-ml
az extension remove -n ml
# ml 拡張機能のインストール
az extension add -n ml
# インストールの確認
az ml -h
次にコマンドを実行して、Job を発行します。
az ml job create -f train-job.yml
結果は Azure Machine Learning studio の Job の画面から確認することができます。