概要
本ページでは Microsoft が定義する MLOps 成熟度モデルの各レベルの概要について説明します。
MLOps 成熟度モデルとは
MLOps 成熟度モデルは MLOps の原則と実践方法を明確にするために策定されました。このモデルを活用することで次の 2 点ができるようになります。
- チーム・組織の MLOps の成熟度を理解する
- MLOps プロジェクトの具体的なゴールや計画を立てる
下記の表は MLOps 成熟度の概要です。
note
この MLOps 成熟度モデルはあくまでベースラインとしてご利用いただき、機械学習システムに求められる要件に応じて、それぞれカスタマイズすることを推奨します。
| Maturity Level | Training Process | Release Process | Integration into app |
|---|---|---|---|
| Level 0 - No MLOps | 追跡されない。アセットは手動で共有される。 | 手動で実行される。 | 主に Data Scientist によって手動で実行される。 |
| Level 1 - DevOps no MLOps | 追跡されない。アセットは手動で共有される。 | 主に Software Engineer によって手動で実行される。 | 主に Data Scientist によって手動で実行される。基本的なテストが導入される。 |
| Level 2 - Automated Training | 追跡される。アセットは再現可能な方法で取得される。 | 主に Software Engineer によって管理されて実行される。 | 主に Data Scientist によって手動で実行される。基本的なテストが導入される。 |
| Level 3 - Automated Model Deployment | 追跡される。アセットは再現可能な方法で取得される。 | CI/CD パイプラインが構築されて自動化される。バージョン管理が導入される。 | 多くの処理が自動で実行されるがまだ手動で実行されるものもある。テストが導入される。 |
| Level 4 - Full MLOps Automated Retraining | 追跡される。アセットは再現可能な方法で取得される。推論システムからのメトリックに基づき再学習が実行される。 | CI/CD パイプラインが構築されて自動化される。バージョン管理が導入される。A/B テストが導入される。 | 多くの処理が自動化されて、最小限の処理のみ手動で実行される。テストが実行される。 |
次のセクションからは各レベルにおける取り組み内容や課題、また、次のレベルにステップにステップアップするために必要なことを説明します。
Level 0 : No MLOps
この段階は機械学習プロジェクトでは PoC や実験フェーズと呼ばれます。Data Scientist は手動で各データソースからデータを取得し、モデルを構築し評価するという作業を探索的にインタラクティブに行います。個人や少人数の Data Scientist が主導します。
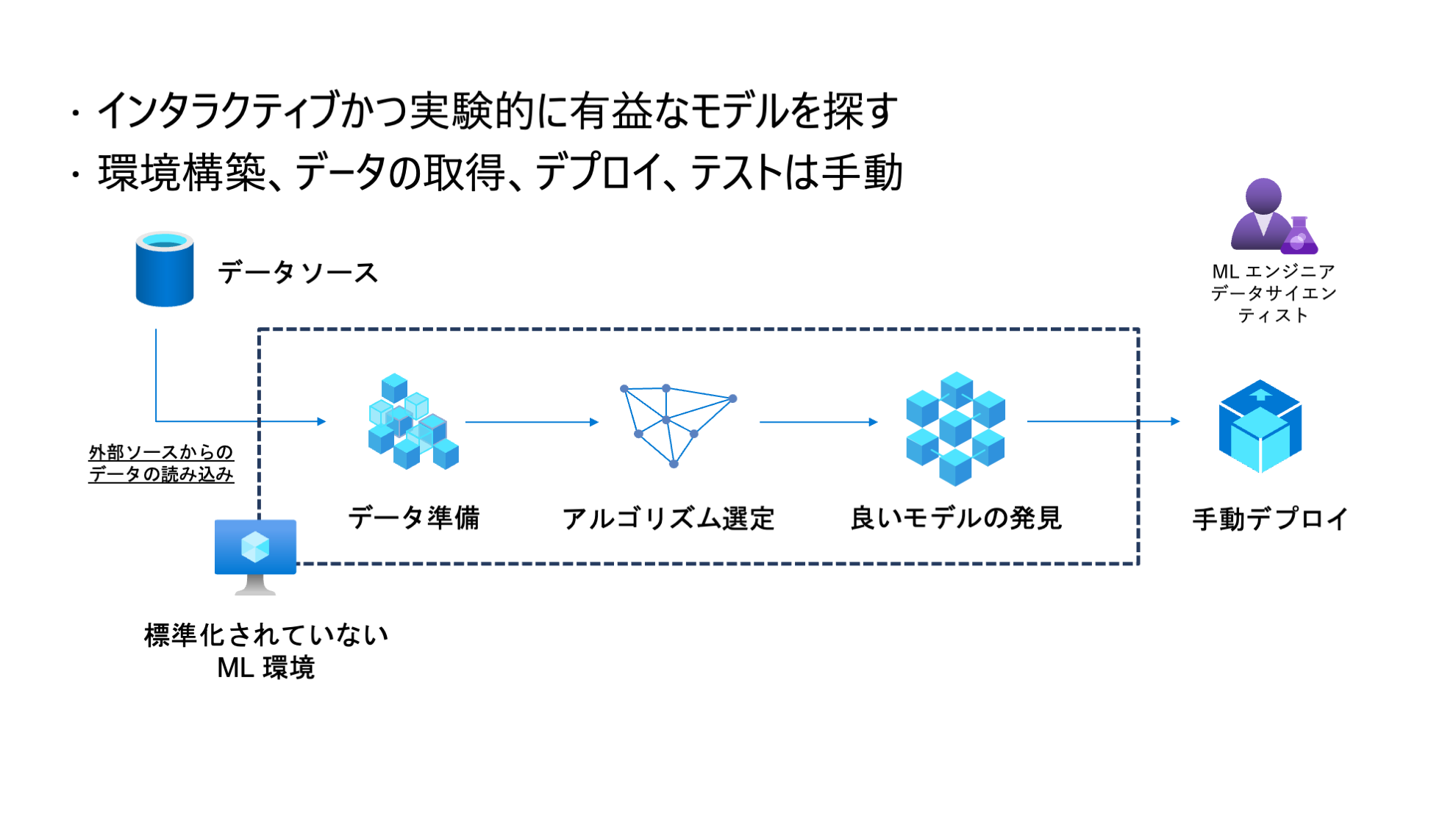
課題
- 再現性
- 個々にデータサイエンティストが独自にカスタマイズした機械学習ツールやコード、Python/Rパッケージを使い学習モデルのジョブを作成しており、組織全体に共有されず学習モデルのジョブを再現することは非常に困難
- 品質とセキュリティ
- テストが設定されていない
- テストポリシーが組織横断的に設計されていない
- 機械学習基盤および成果物が管理されておらず、セキュリティ上の懸念がある
- スケーラビリティ
- 大規模なジョブを実行するのに十分なパワーの計算リソースがない
- 高価な計算リソースが属人的に管理・使用されて組織内で共有されていないため、コスト増につながる
- その他
- 機械学習用のデータソースが整備されておらず、学習データの取得に手作業が必要
次のレベルに進むために
- 機械学習プラットフォームの整備
- チーム・組織で共有の機械学習プラットフォームを利用していること
- コードを集約するリポジトリホスティング環境の整備
- テストの自動化
- 少なくともコードに対するテスト項目がルール化されており、テストの実行が自動化できていること
- データ基盤が整備され始めていること
Level 1 : DevOps no MLOops
この段階では Data Scientist は組織で標準化された機械学習システムで作業をしています。データパプラインは Data Engineer によって整備され、容易に学習データを取得することができます。
しかしながら、利用したデータや Python パッケージといったアセットが共有されておらず、モデル学習の再現性には課題があります。またデータを取得し、特徴量エンジニアリングを行い、モデルを選択し構築をするという一連のワークフローが複雑であり、他の Data Scientist に共有されていないため再現性が低い状態です。
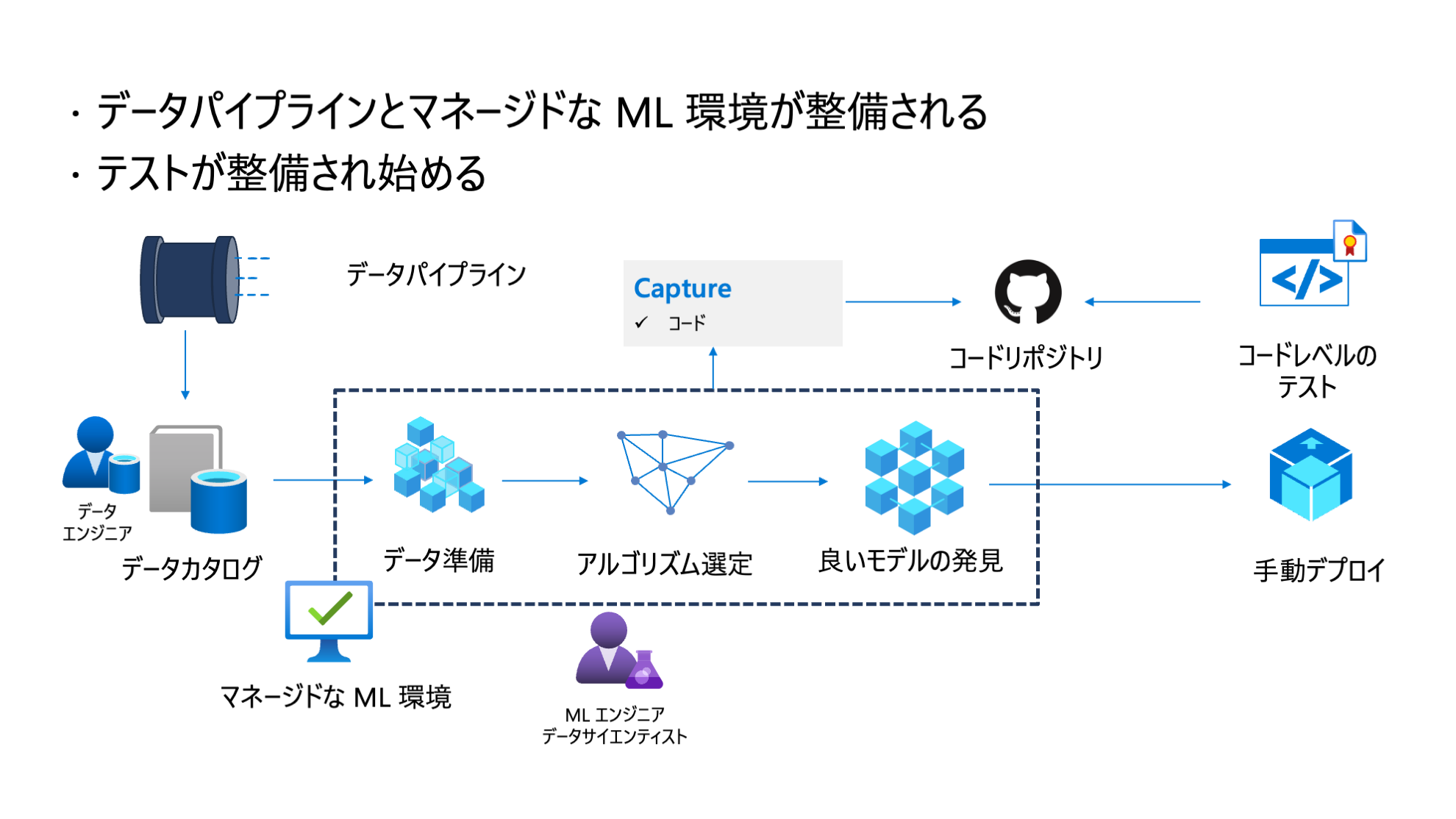
課題
- 再現性
- 機械学習の実験記録が共有可能な形で取られておらず、実験およびジョブの再現が困難
- 機械学習のライフサイクルを構成するアセットが組織間で共有されていない
- 学習モデルワークフローの中に複雑なジョブの依存関係があり、開発者に属人的となっている
次のレベルに進むために
モデル学習の再現性確保
- 1度やった実験を再現しようと思えばでき、実験の成果物(学習済みモデル等)が実験と紐づいた形で保管されていること
- パイプラインが構築され、確立した手順は簡単に再実行できること
モデルの運用管理
- モデルが管理されており、関連する実験やエンドポイント (推論環境) が紐づくこと
Level 2 : Automated Training
この段階では Data Scientist はパイプラインの技術を利用してモデル学習の一連のワークフローを再現することができています。アセットやメタデータは自動で取得されます。
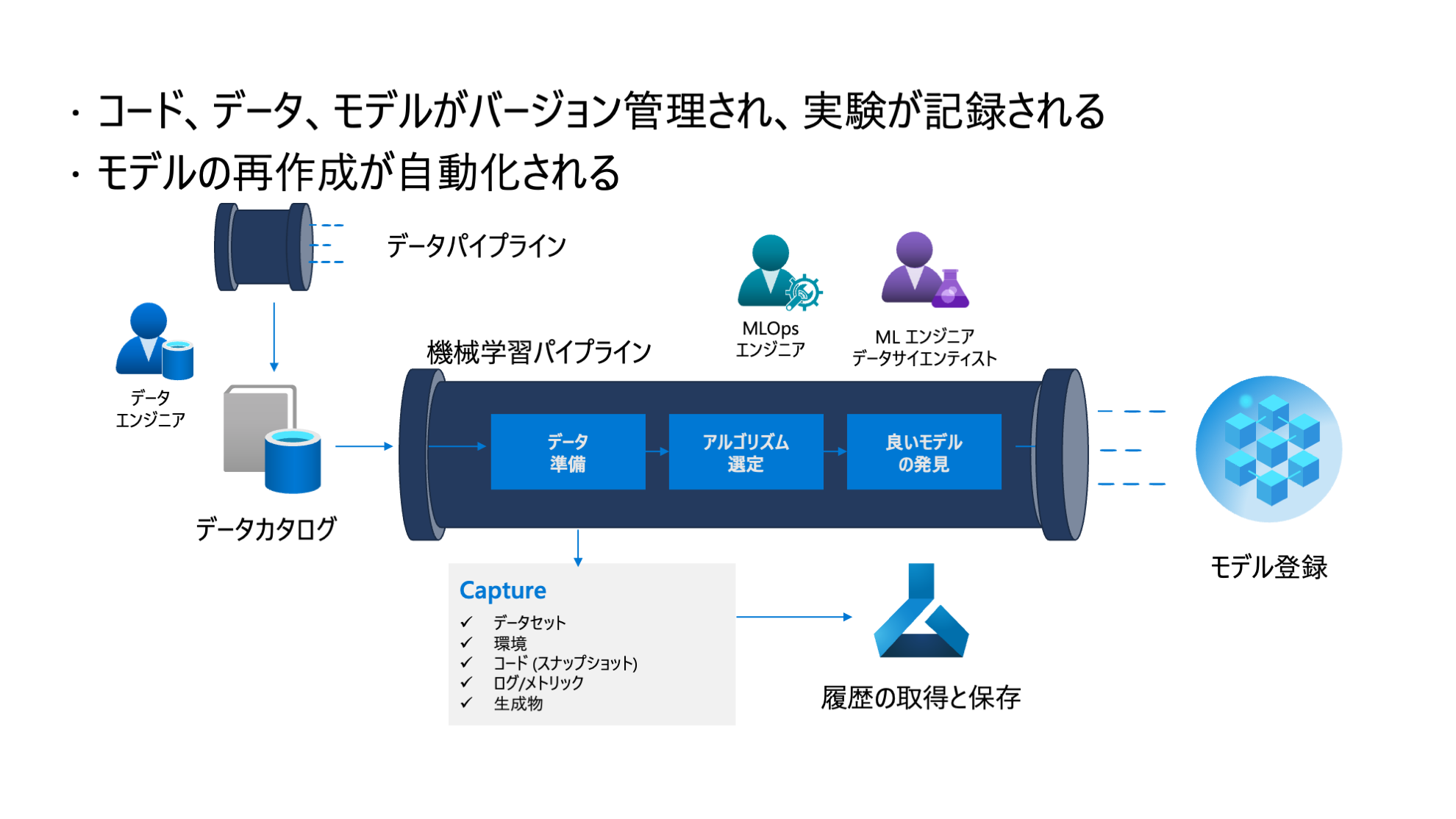
課題
デプロイ
- モデルの用途によって推論環境の実装方法が毎回異なり、デプロイ手順が散在している
- デプロイ手順が属人化しており共有されておらず、再実行が難しい
品質とセキュリティ
- 学習されたモデルの挙動と性能が求める要件を満たしているか検証する手順 (QA) が標準化されていない
- 機械学習モデルのテスト工程が全く自動化されていない
- ステークホルダーにモデルの解釈可能性、説明可能性、公平性等のモデルの信頼性について説明をする必要がある
次のレベルに進むために
推論環境に合わせたデプロイパイプラインの実装
- データを受け取って機械学習モデルによる推論結果を返すコンテナをビルドし Kubernetes 等のコンテナを動かす基盤上にデプロイする一連の作業を実行するパイプラインを構築
- データソースからデータを取得し、機械学習モデルによる推論結果を得てデータを格納するバッチ処理を実行するパイプラインを構築する
モデルの検証・品質確認を行う仕組みの実装
- テストデータ(ゴールドデータ)による精度検証の自動化
- 説明性、公平性の確認
Level 3 : Automated Model Deployment
このレベルでは、学習済みモデルのデプロイが自動化されています。人間の関与は必要最低限に留まっており、人的なミスが除去され、品質、セキュリティ、コンプライアンスのレベルが高い状態です。
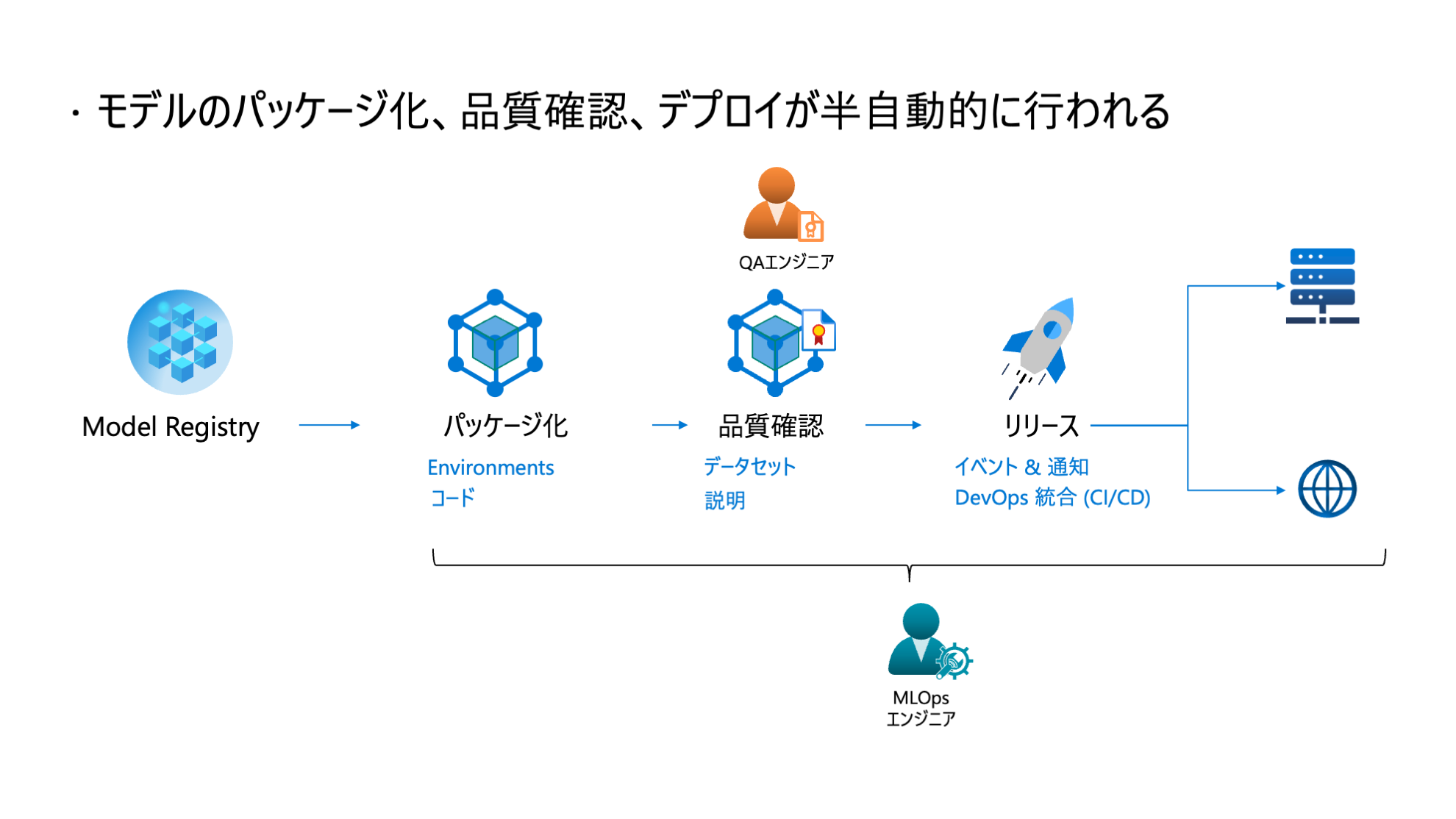
課題
監視
- 推論環境およびモデルの推論性能の監視が十分でない
- データの監視が十分でない
- 再トレーニングの基準となる KPI およびその閾値の設定ができていない
品質
- デプロイ後モデルが適切なタイミングでアップグレードされていない
- 新しいモデルを本番の推論環境にデプロイする場合に、ユーザーへの影響を最小化できていない
スケーラビリティ
- システム全体に自動化可能にも関わらず手動実行が必要な部分が多数存在する
次のレベルに進むために
- 機械学習モデルの性能劣化や劣化につながる要因を検知するための監視体制を整備する
- 機械学習モデルの性能を評価できる指標の洗い出し
- 指標の算出に必要なログの収集とニアリアルタイムな指標算出の仕組み構築
- データセットの変動を検知する仕組みの構築
- 自動化の仕組みを実装する
- 学習からデプロイまでの各工程を間断なく処理する仕組みの実装
- ブルー・グリーンデプロイと新モデルの挙動を自動的に監視対象に含める仕組みの構築
- 異常検知時の通知や定型的作業の自動実行
- 再学習・再展開を実行する指標の閾値設定とトリガーの実装
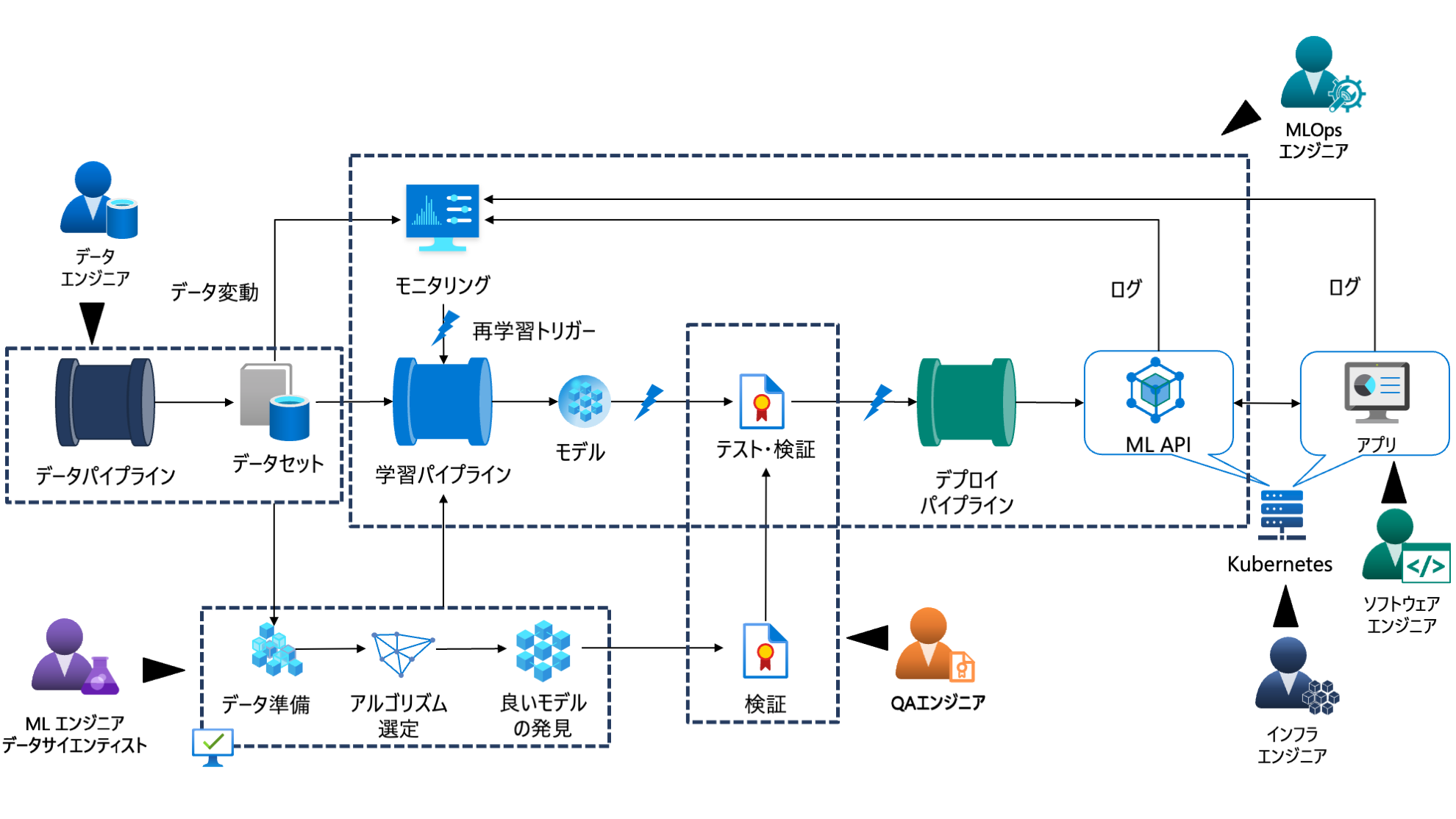
Level 4 : Full MLOps Automated Retraining
この段階では、モニタリングの仕組みや再実験・再学習の仕組みが導入されており、継続的な機械学習システムの改善ができる状態です。